The many histograms in sections (a)-(c) of Part 3 reflect fantastic p-values (probability that the outcome occurred by chance) for Dennis Rodman’s win percentage differentials relative to other players, but, technically, this doesn’t say anything about the p-values of each metric in itself. What this means is, while we have confidently established that Rodman’s didn’t just get lucky in putting up better numbers than his peers, we haven’t yet established the extent to which his being one of the best players by this measure actually proves his value. This is probably a minor distinction to all but my most nitpicky readers, but it is exactly one of those nagging “little insignificant details” that ends up being a key to the entire mystery.
{kind=link}
{kind=link}
The Technical Part (Feel Free to Skip)
The challenge here is this: My preferred method for rating the usefulness and reliability of various statistics is to see how accurate they are at predicting win differentials. But, now, the statistic I would like to test actually is win differential. The problem, of course, is that a player’s win differential is always going to be exactly identical to his win differential. If you’re familiar with the halting problem or Gödel’s incompleteness theorem, you probably know that this probably isn’t directly solvable: that is, I probably can’t design a metric for evaluating metrics that is capable of evaluating itself.
To work around this, our first step must be to independently assess the reliability of win predictions that are based on our inputs. As in sections (b) and (c), we should be able to do this on a team-by-team basis and adapt the results for player-by-player use. Specifically, what we need to know is the error distribution for the outcome-predicting equation—but this raises its own problems.
Normally, to get an error distribution of a predictive model, you just run the model a bunch of times and then measure the predicted results versus the actual results (calculating your average error, standard deviation, correlation, whatever). But, because my regression was to individual games, the error distribution gets “black-boxed” into the single-game win probability.
[A brief tangent: “Black box” is a term I use to refer to situations where the variance of your input elements gets sucked into the win percentage of a single outcome. E.g., in the NFL, when a coach must decide whether to punt or go for it on 4th down late in a game, his decision one way or the other may be described as “cautious” or “risky” or “gambling” or “conservative.” But these descriptions are utterly vapid: with respect to winning, there is no such thing as a play that is more or less “risky” than any other—there are only plays that improve your chances of winning and plays that hurt them. One play may seem like a bigger “gamble,” because there is a larger immediate disparity between its possible outcomes, but a 60% chance of winning is a 60% chance of winning. Whether your chances comes from superficially “risky” plays or superficially “cautious” ones, outside the “black box” of the game, they are equally volatile.]
For our purposes, what this means is that we need to choose something else to predict: specifically, something that will have an accurate and measurable error distribution. Thus, instead of using data from 81 games to predict the probability of winning one game, I decided to use data from 41 season-games to predict a team’s winning percentage in its other 41 games.
To do this, I split every team season since 1986 in half randomly, 10 times each, leading to a dataset of 6000ish randomly-generated half-season pairs. I then ran a logistic regression from each half to the other, using team winning percentage and team margin of victory as the input variables and games won as the output variable. I then measured the distribution of those outcomes, which gives us a baseline standard deviation for our predicted wins metric for a 41 game sample.
Next, as I discussed briefly in section (b), we can adapt the distribution to other sample sizes, so long as everything is distributed normally (which, at every point in the way so far, it has been). This is a feature of the normal distribution: it is easy to predict the error distribution of larger and smaller datasets—your standard deviation will be directly proportional to the square-root of the ratio of the new sample size to the original sample size.
Since I measured the original standard deviations in games, I converted each player’s “Qualifying Minutes” into “Qualifying Games” by dividing by 36. So the sample-size-adjusted standard deviation is calculated like this:
Since the metrics we’re testing are all in percentages, we then divide the new standard deviation by the size of the sample, like so:
This gives us a standard deviation for actual vs. predicted winning percentages for any sample size. Whew!
The Good, Better, and Best Part
The good news is: now that we can generate standard deviations for each player’s win differentials, this allows us to calculate p-values for each metric, which allows us to finally address the big questions head on: How likely is it that this player’s performance was due to chance? Or, put another way: How much evidence is there that this player had a significant impact on winning?
The better news is: since our standard deviations are adjusted for sample size, we can greatly increase the size of the comparison pool, because players with smaller samples are “punished” accordingly. Thus, I dropped the 3-season requirement and the total minutes requirement entirely. The only remaining filters are that the player missed at least 15 games for each season in which a differential is computed, and that the player averaged at least 15 minutes per game played in those seasons. The new dataset now includes 1539 players.
Normally I don’t weight individual qualifying seasons when computing career differentials for qualifying players, because the weights are an evidentiary matter rather than an impact matter: when it comes to estimating a player’s impact, conceptually I think a player’s effect on team performance should be averaged across circumstances equally. But this comparison isn’t about whose stats indicate the most skill, but whose stats make for the best evidence of positive contribution. Thus, I’ve weighted each season (by the smaller of games missed or played) before making the relevant calculations.
So without further ado, here are Dennis Rodman’s statistical significance scores for the 4 versions of Win % differential, as well as where he ranks against the other players in our comparison pool:

Note: I’ve posted a complete table of z scores and p values for all 1539 players on the site. Note also that due to the weighting, some of the individual differential stats will be slightly different from their previous values.
You should be careful to understand the difference between this table of p-values and ranks vs. similar ones from earlier sections. In those tables, the p-value was determined by Rodman’s relative position in the pool, so the p-value and rank basically represented the same thing. In this case, the p-value is based on the expected error in the results. Specifically, they are the answer to the question “If Dennis Rodman actually had zero impact, how likely would it be for him to have posted these differentials over a sample of this size?” The “rank” is then where his answer ranks among the answers to the same question for the other 1538 players. Depending on your favorite flavor of win differential, Rodman ranks anywhere from 1st to 8th. His average rank among those is 3.5, which is 2nd only to Shaquille O’Neal (whose differentials are smaller but whose sample is much larger).
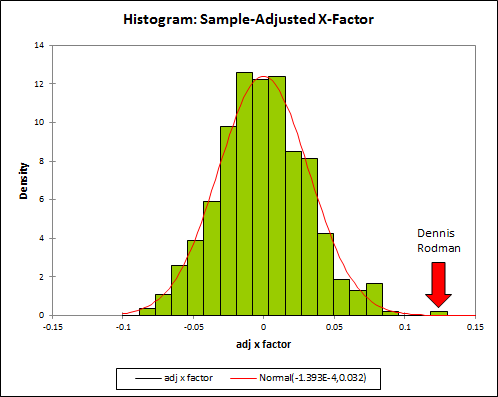
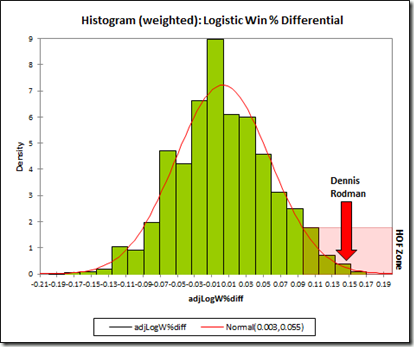
Of course, my preference is for the combined/adjusted stat. So here is my final histogram:

Note: N=1539.
Now, to be completely clear, as I addressed in Part 3(a) and 2(b), so that I don’t get flamed (or stabbed, poisoned, shot, beaten, shot again, mutilated, drowned, and burned—metaphorically): Yes, actually I AM saying that, when it comes to empirical evidence based on win differentials, Rodman IS superior to Michael Jordan. This doesn’t mean he was the better player: for that, we can speculate, watch the tape, or analyze other sources of statistical evidence all day long. But for this source of information, in the final reckoning, win differentials provide more evidence of Dennis Rodman’s value than they do of Michael Jordan’s.
The best news is: That’s it. This is game, set, and match. If the 5 championships, the ridiculous rebounding stats, the deconstructed margin of victory, etc., aren’t enough to convince you, this should be: Looking at Win% and MOV differentials over the past 25 years, when we examine which players have the strongest, most reliable evidence that they were substantial contributors to their teams’ ability to win more basketball games, Dennis Rodman is among the tiny handful of players at the very very top.