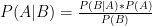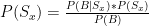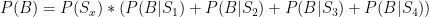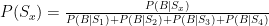Going into the final round of ESPN’s Stat Geek Smackdown, I found myself 4 points behind leader Stephen Ilardi, with only 7 points left on the table: 5 for picking the final series correctly, and a bonus 2 for also picking the correct number of games. The bottom line being, the only way I could win is if the two of us picked opposite sides. Thus, with Miami being a clear (though not insurmountable) favorite in the Finals, I picked Dallas. As noted in the ESPN write-up”
“The Heat,” says Morris, “have a better record, home-court advantage, a better MOV [margin of victory], better SRS [simple rating system], more star power, more championship experience, and had a tougher road to the Finals. Plus Miami’s poor early-season performance can be fairly discounted, and it has important players back from injury. Thus, my model heavily favors Miami in five or six games.
But I’m sure Ilardi knows all this, so, since I’m playing to win, I’ll take Dallas. Of course, I’m gambling that Ilardi will play it safe and stick with Miami himself since I’m the only person close enough to catch him. If he assumes I will switch, he could also switch to Dallas and sew this thing up right now. Game-theoretically, there’s a mixed-strategy Nash equilibrium solution to the situation, but without knowing any more about the guy, I have to assume he’ll play it like most people would. If he’s tricky enough to level me, congrats.
Since I actually bothered to work out the equilibrium solution, I thought some of you might be interested in seeing it. Also, the situation is well-suited to illustrate a couple of practical points about how and when you should incorporate game-theoretic strategies in real life (or at least in real games).
Some Game Theory Basics
Certainly many of my readers are intimately familiar with game theory already (some probably much more than I am), but for those who are less so, I thought I should explain what a “mixed-strategy Nash equilibrium solution” is, before getting into the details on the Smackdown version (really, it’s not as complicated as it sounds).
A set of strategies and outcomes for a game is an “equilibrium” (often called a “Nash equilibrium”) if no player has any reason to deviate from it. One of the most basic and most famous examples is the “prisoner’s dilemma” (I won’t get into the details, but if you’re not familiar with it already, you can read more at the link): the incentive structure of that game sets up an equilibrium where both prisoners rat on each other, even though it would be better for them overall if they both kept quiet. “Rat/Rat” is an equilibrium because an individual deviating from it will only hurt themselves. Bother prisoners staying silent is NOT an equilibrium, because either can improve their situation by switching strategies (note that games can also have multiple equilibriums, such as the “Which Side of the Road To Drive On” game: both “everybody drives on the left” and “everybody drives on the right” are perfectly good solutions).
But many games aren’t so simple. Take “Rock-Paper-Scissors”: If you pick “rock,” your opponent should pick “paper,” and if he picks “paper,” you should take “scissors,” and if you take “scissors,” he should take “rock,” etc, etc—at no point does the cycle stop with everyone happy. Such games have equilibriums as well, but they involve “mixed” (as opposed to “pure”) strategies (trivia note: John Nash didn’t actually discover or invent the equilibrium named after him: his main contribution was proving that at least one existed for every game, using his own proposed definitions for “strategy,” “game,” etc). Of course, the equilibrium solution to R-P-S is for each player to pick completely at random.
If you play the equilibrium strategy, it is impossible for opponents to gain any edge on you, and there is nothing they can do to improve their chances—even if they know exactly what you are going to do. Thus, such a strategy is often called “unexploitable.” The downside, however, is that you will also fail to punish your opponents for any “exploitable” strategies they may employ: For example, they can pick “rock” every time, and will win just as often.
The Smackdown Game
The situation between Ilardi and I going into our final Smackdown picks is just such a game: If Ilardi picked Miami, I should take Dallas, but if I picked Dallas, he should take Dallas, in which case I should take Miami, etc. When you find yourself in one of these “loops,” generally it means that the equilibrium solution is a mixed strategy.
Again, the equilibrium solution is the set of strategies where neither of us has any incentive to deviate. While finding such a thing may sound difficult in theory, for 2-player games it’s actually pretty simple intuitively, and only requires basic algebra to compute.
First, you start with one player, and find their “break-even” point: that is, the strategy their opponent would have to employ for them to be indifferent between their own strategic options. In this case, this meant: How often would I have to pick Miami for Miami and Dallas to be equally good options for Ilardi, and vice versa.
So let’s formalize it a bit: “EV” is the function “Expected Value.” Let’s call Ilardi or I picking Miami “iM” and “bM,” and Ilardi or I picking Dallas “iD” and “bD,” respectively. Ilardi will be indifferent between picking Miami and Dallas when the following is true:
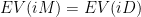
Let’s say “WM” = the odds of the Heat winning the series. So now we need to find EV(iM) in terms of bM and WM. If Ilardi picks Miami, he wins every time I pick Miami, and every time Miami wins when I pick Dallas. Thus his expected value for picking Miami is as follows:

When he picks Dallas, he wins every time I don’t pick Miami, and every time Miami loses when I do:

Setting these two equations equal to each other, the point of indifference can be expressed as follows:

Solving for bM, we get:

What this tells us is MY equilibrium strategy. In other words, if I pick Miami exactly as often as we expect Miami to lose, it doesn’t matter whether Ilardi picks Miami or Dallas, he will win just as often either way.
Now, to find HIS equilibrium strategy, we repeat the process to find the point where I would be indifferent between picking Miami or Dallas:


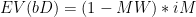
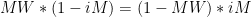
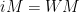
In other words, if Ilardi picks Miami exactly as often as they are expected to win, it doesn’t matter which team I pick.
Note the elegance of the solution: Ilardi should pick each team exactly as often as they are expected to win, and I should pick each team exactly as often as they are expected to lose. There are actually a lot of theorems and such that you’d learn in a Game Theory class that make identifying that kind of situation much easier, but I’m pretty rusty on that stuff myself.
So how often would each of us win in the equilibrium solution? To find this, we can just solve any of the EV equations above, substituting the opposing player’s optimal strategy for the variable representing the same. So let’s use the EV(iM) equation, substituting (1-WM) anywhere bM appears:
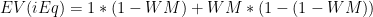
Simplify:

Here’s a graph of the function:

Obviously, it doesn’t matter which team is favored: Ilardi’s edge is weakest when the series is a tossup, where he should win 75% of the time. The bigger a favorite one team is, the bigger the leader’s advantage.
Now let’s Assume Miami was expected to win 63% of the time (approximately the consensus), the Nash Equilibrium strategy would give Ilardi a 76.7% chance of winning, which is obviously considerably better than the 63% chance that he ended up with by choosing Miami to my Dallas—so the actual picks were a favorable outcome for me. Of course, that’s not to say his decision was wrong from his perspective: Either of us could have other preferences that come into play—for example, we might intrinsically value picking the Finals correctly, or someone in my spot (though probably not me) might care more about securing their 2nd-place finish than about having a chance to overtake the leader, or Ilardi might want to avoid looking bad if he “outsmarted himself” by picking Dallas while I played straight-up and stuck with Miami.
But even assuming we both wanted to maximize our chances of winning the competition, picking Miami may still have been Ilardi’s best strategy given when he knew at the time, and it would have been a fairly common outcome if we had both played game-theoretically anyway. Which brings me to the main purpose for this post:
A Little Meta-Strategy
In reality, neither of us played our equilibrium strategies. I believed Ilardi would pick Miami more than 63% of the time, and thus the correct choice for me was to pick Dallas. Assuming Ilardi believed I would pick Dallas less than 63% of the time, his best choice was to pick Miami. Indeed, it might seem almost foolhardy to actually play a mixed strategy: what are the chances that your opponent ever actually makes a certain choice exactly 37% of the time? Whatever your estimation, you should go with whichever gives you the better expected value, right?
This is a conundrum that should be familiar to any serious poker players out there. E.g., at the end of the hand, you will frequently find yourself in an “is he bluffing or not?” (or “should I bluff or not?”) situation. You can work out the game-theoretically optimal calling (or bluffing) rate and then roll a die in your head. But really, what are the chances that your opponent is bluffing exactly the correct percentage of the time? To maximize your expected value, you gauge your opponent’s chances of bluffing, and if you have the correct pot odds, you call or fold (or raise) as appropriate.
So why would you ever play the game-theoretical strategy, rather than just making your best guess about what your opponent is doing and responding to that? There are a couple of answers to this. First, in a repeating game, there can be strategic advantages to having your opponent know (or at least believe) that you are playing such a strategy. But the slightly trickier—and for most people, more important—answer is that your estimation might be wrong: playing the “unexploitable” strategy is a defensive maneuver that ensures your opponent isn’t outsmarting you.
The key is that playing any “exploiting” strategy opens you up to be exploited yourself. Think again of Rock-Paper-Scissors: If you’re pretty sure your opponent is playing “rock” too often, you can try to exploit them by playing “paper” instead of randomizing—but this opens you up for the deadly “scissors” counterattack. And if your opponent is a step ahead of you (or a level above you), he may have anticipated (or even set up) your new strategy, and has already prepared to take advantage.
Though it may be a bit of an oversimplification, I think a good meta-strategy for this kind of situation—where you have an equilibrium or “unexploitable” strategy available, but are tempted to play an exploiting but vulnerable strategy instead—is to step back and ask yourself the following question: For this particular spot, if you get into a leveling contest with your opponent, who is more likely to win? If you believe you are, then, by all means, exploit away. But if you’re unsure about his approach, and there’s a decent chance he may anticipate yours—that is, if he’s more likely to be inside your head than you are to be inside his—your best choice may be to avoid the leveling game altogether. There’s no shame in falling back on the “unexploitable” solution, confident that he can’t possibly gain an advantage on you.
Back in Smackdown-land: Given the consensus view of the series, again, the equilibrium strategy would have given Ilardi about a 77% chance of winning. And he could have announced this strategy to the world—it wouldn’t matter, as there’s nothing I could have done about it. As noted above, when the actual picks came out, his new probability (63%) was significantly lower. Of course, we shouldn’t read too much into this: it’s only a single result, and doesn’t prove that either one of us had an advantage. On the other hand, I did make that pick in part because I felt that Ilardi was unlikely to “outlevel” me. To be clear, this was not based on any specific assessment about Ilardi personally, but based my general beliefs about people’s tendencies in that kind of situation.
Was I right? The outcome and reasoning given in the final “picking game” has given me no reason to believe otherwise, though I think that the reciprocal lack of information this time around was a major part of that advantage. If Ilardi and I find ourselves in a similar spot in the future (perhaps in next year’s Smackdown), I’d guess the considerations on both sides would be quite different.