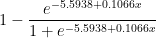So despite my general antipathy toward America’s pastime, I’ve been looking into baseball a lot lately. I’m working on a three part series that will “take on” Pythagorean Expectation. But considering the sanctity of that metric, I’m taking my time to get it right.
For now, the big news is that Major League Baseball is finally going to have realignment, which will most likely lead to an extra playoff team, and a one game Wild Card series between the non–division winners. I’m not normally one who tries to comment on current events in sports (though, out of pure frustration, I almost fired up WordPress today just to take shots at Tim Tebow—even with nothing original to say), but this issue has sort of a counter-intuitive angle to it that motivated me to dig a bit deeper.
Conventional wisdom on the one game playoff is pretty much that it’s, well, super crazy. E.g., here’s Jayson Stark’s take at ESPN:
But now that the alternative to finishing first is a ONE-GAME playoff? Heck, you’d rather have an appendectomy than walk that tightrope. Wouldn’t you?
Though I think he actually likes the idea, precisely because of the loco factor:
So a one-game, October Madness survivor game is what we’re going to get. You should set your DVRs for that insanity right now.
In the meantime, we all know what the potential downside is to this format. Having your entire season come down to one game isn’t fair. Period.
I wouldn’t be too sure about that. What is fair? As I’ve noted, MLB playoffs are basically a crapshoot anyway. In my view, any move that MLB can make toward having the more accomplished team win more often is a positive step. And, as crazy as it sounds, that is likely exactly what a one game playoff will do.
The reason is simple: home field advantage. While smaller than in other sports, the home team in baseball still wins around 55% of the time, and more games means a smaller percentage of your series games played at home. While longer series’ eventually lead to better teams winning more often, the margins in baseball are so small that it takes a significant edge for a team to prefer to play ANY road games:

Note: I calculated these probabilities using my favorite binom.dist function in Excel. Specifically, where the number of games needed to win a series is k, this is the sum from x=0 to x=k of the p(winning x home games) times p(winning at least k-x road games).
So assuming each team is about as good as their records (which, regardless of the accuracy of the assumption, is how they deserve to be treated), a team needs about a 5.75% generic advantage (around 9-10 games) to prefer even a seven game series to a single home game.
But what about the incredible injustice that could occur when a really good team is forced to play some scrub? E.g., Stark continues:
It’s a lock that one of these years, a 98-win wild-card team is going to lose to an 86-win wild-card team. And that will really, really seem like a miscarriage of baseball justice. You’ll need a Richter Scale handy to listen to talk radio if that happens.
But you know what the answer to those complaints will be?
“You should have finished first. Then you wouldn’t have gotten yourself into that mess.”
Stark posits a 12 game edge between two wild card teams, and indeed, this could lead to a slightly worse spot for the better team than a longer series. 12 games corresponds to a 7.4% generic advantage, which means a 7-game series would improve the team’s chances by about 1% (oh, the humanity!). But the alternative almost certainly wouldn’t be seven games anyway, considering the first round of the playoffs is already only five. At that length, the “miscarriage of baseball justice” would be about 0.1% (and vs. 3 games, sudden death is still preferable).
If anything, consider the implications of the massive gap on the left side of the graph above: If anyone is getting screwed by the new setup, it’s not the team with the better record, it’s a better team with a worse record, who won’t get as good a chance to demonstrate their actual superiority (though that team’s chances are still around 50% better than they would have been under the current system). And those are the teams that really did “[get themselves] into that mess.”
Also, the scenario Stark posits is extremely unlikely: basically, the difference between 4th and 5th place is never 12 games. For comparison, this season the difference between the best record in the NL and the Wild Card Loser was only 13 games, and in the AL it was only seven. Over the past ten seasons, each Wild Card team and their 5th place finisher were separated by an average of 3.5 games (about 2.2%):

Note that no cases over this span even rise above the seven game “injustice line” of 5.75%, much less to the nightmare scenario of 7.5% that Stark invokes. The standard deviation is about 1.5%, and that’s with the present imbalance of teams (note that the AL is pretty consistently higher than the NL, as should be expected)—after realignment, this plot should tighten even further.
Indeed, considering the typically small margins between contenders in baseball, on average, this “insane” sudden death series may end up being the fairest round of the playoffs.